
11. Nov. 2025
Denkprozess großer Sprachmodelle (LLMs)


Ein neuer Ansatz: Modelle, die sich selbst verstehen
Große Sprachmodelle verarbeiten Eingabetexte schrittweise – Schicht für Schicht.
Jede dieser Schichten bildet eine Art Denkebene, auf der das Modell Informationen verdichtet, Bedeutungen verändert und semantische Beziehungen neu anordnet. Diese Veränderungen zeigen sich in den sogenannten Hidden States, also den internen Aktivierungen zwischen den Layern. Sie lassen sich als Bewegung im semantischen Raum darstellen:
- d₁ beschreibt die Geschwindigkeit dieser Bewegung – wie stark sich die Bedeutung eines Tokens oder Satzes zwischen zwei Schichten verändert.
- d₂ misst die Krümmung oder Richtungsänderurung – also, ob der Denkpfad des Modells eher geradlinig oder verschlungen verläuft.
Durch die Kombination beider Werte entsteht ein Energiewert E = d₁ + d₂ , der als Maß für die innere Aktivität und Kohärenz des Denkprozesses dient. Je stabiler und harmonischer diese Bewegung ist, desto strukturierter scheint das Modell zu denken. So wird aus einem abstrakten mathematischen Signal ein greifbarer Indikator für die Qualität des internen Reasonings.
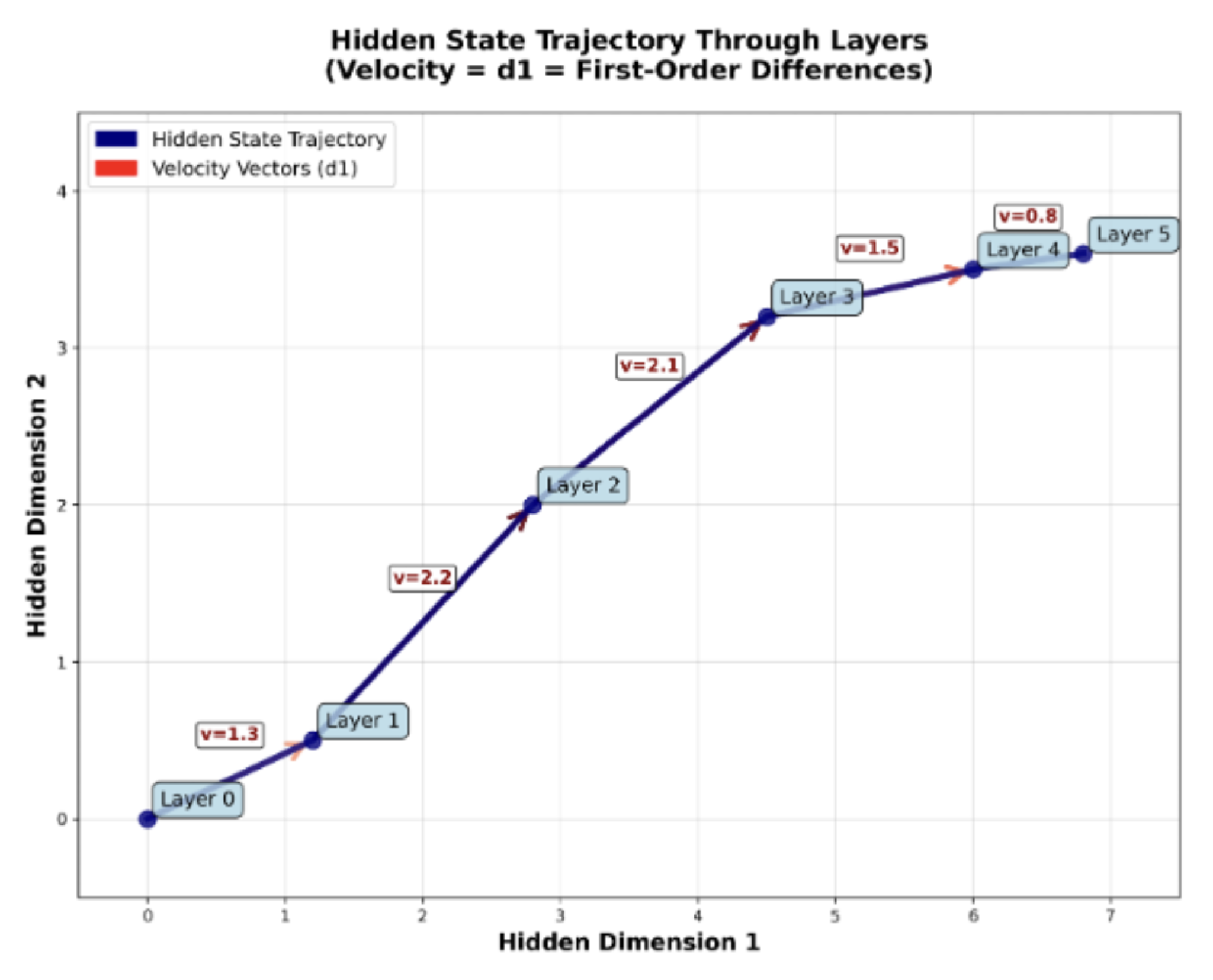
Abbildung 1.1: Beispiel mit 2 Dimensionen für Geschwindigkeit (In der Realität haben die Sprachmodelle tausende von Dimensionen pro Schicht.)
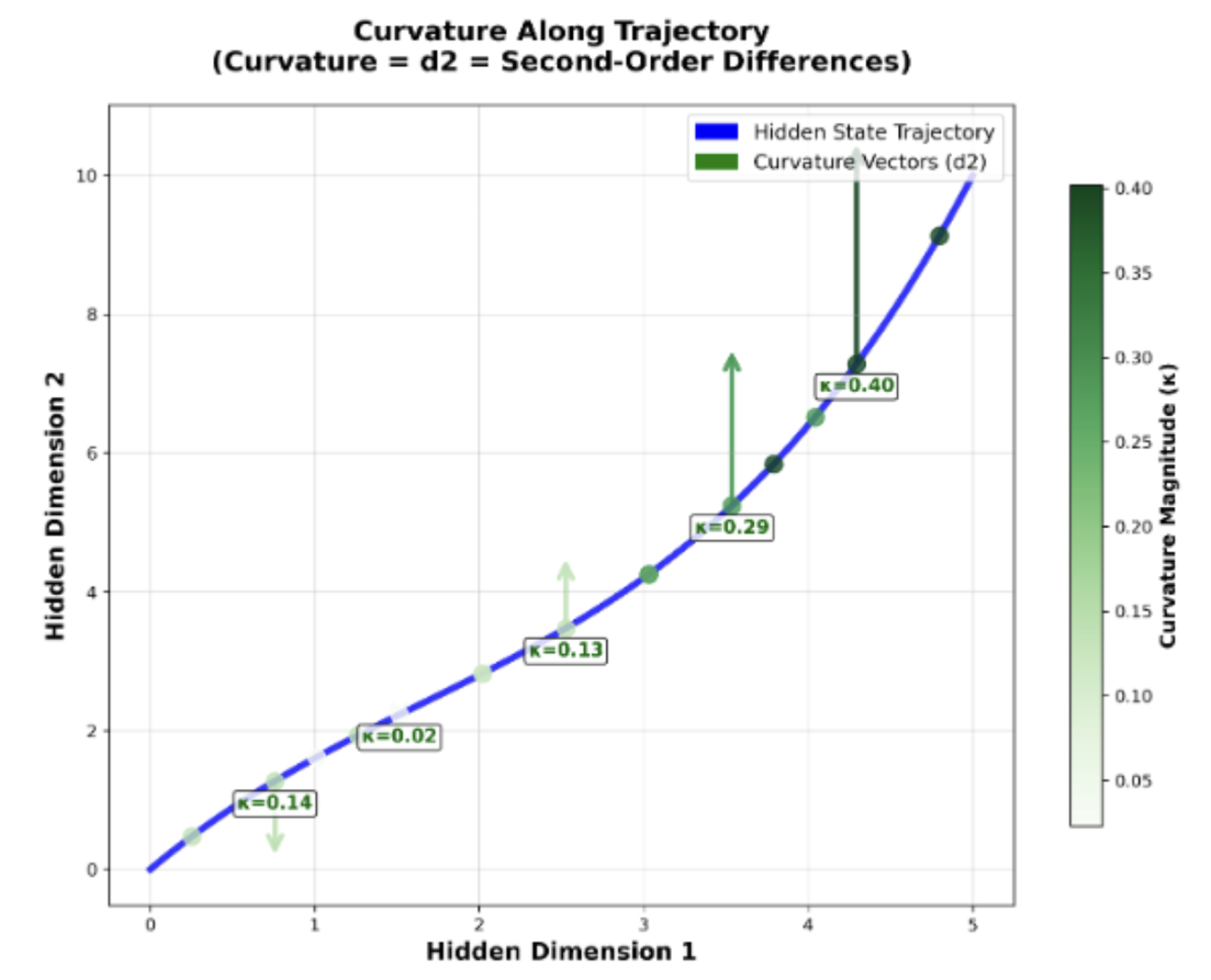
Abbildung 1.2: Beispiel mit 2 Dimensionen für Krümmung
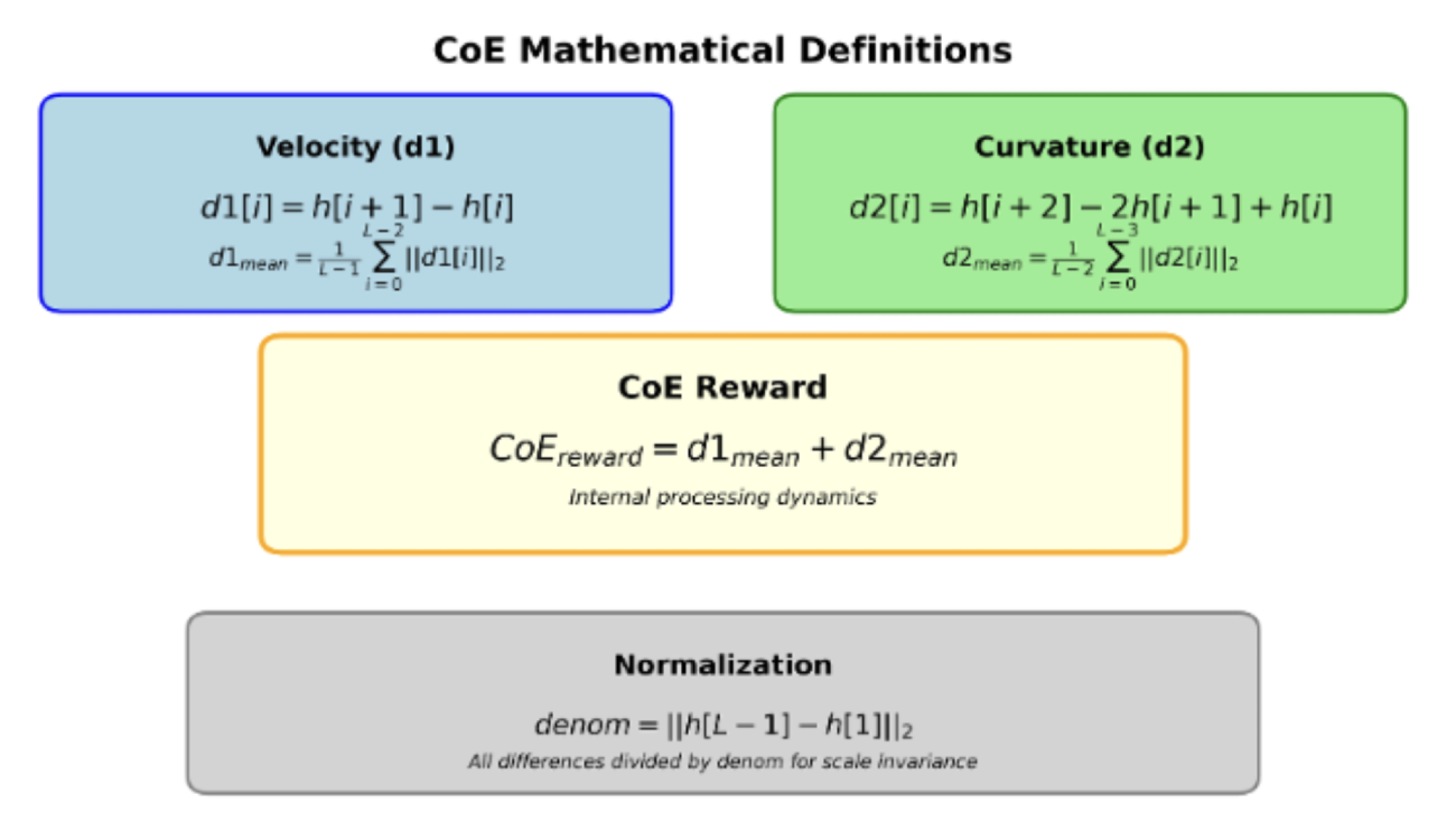
Abbildung 1.3: Die Energie (oder Reward) kalkuliert aus den Hidden States
Vom Konzept zur Umsetzung
Für seine Experimente nutzte Hajrullahu die open-source Qwen2.5-Instruct Modelle mit 1.5, 3 und 7 Milliarden Parametern – moderne Transformer Netzwerke, die bereits auf breiten Datensätzen vortrainiert sind. Die Hidden States wurden aus allen Schichten extrahiert und anschließend statistisch ausgewertet, um ihre Veränderung zwischen den Ebenen zu messen. Dabei kamen Technologien wie Python, PyTorch, Ray und das Framework EasyR1 zum Einsatz, betrieben auf Hochleistungsclustern.
Als Datengrundlage dienten zwei Benchmarks:
- Math12k, ein Datensatz für komplexe mathematische Aufgaben, und
- GSM8k, der sich auf natürlichsprachliche Schritt-für-Schritt-Problemlösungen konzentriert.
Durch den Vergleich dieser beiden Aufgabenarten konnte gezeigt werden, dass interne Energieverläufe in semantisch kohärenten Aufgaben stabile Muster zeigen als in streng formalen Aufgaben. Damit gelang ein quantitativer Blick auf den „Gedankenfluss“ eines Sprachmodells.
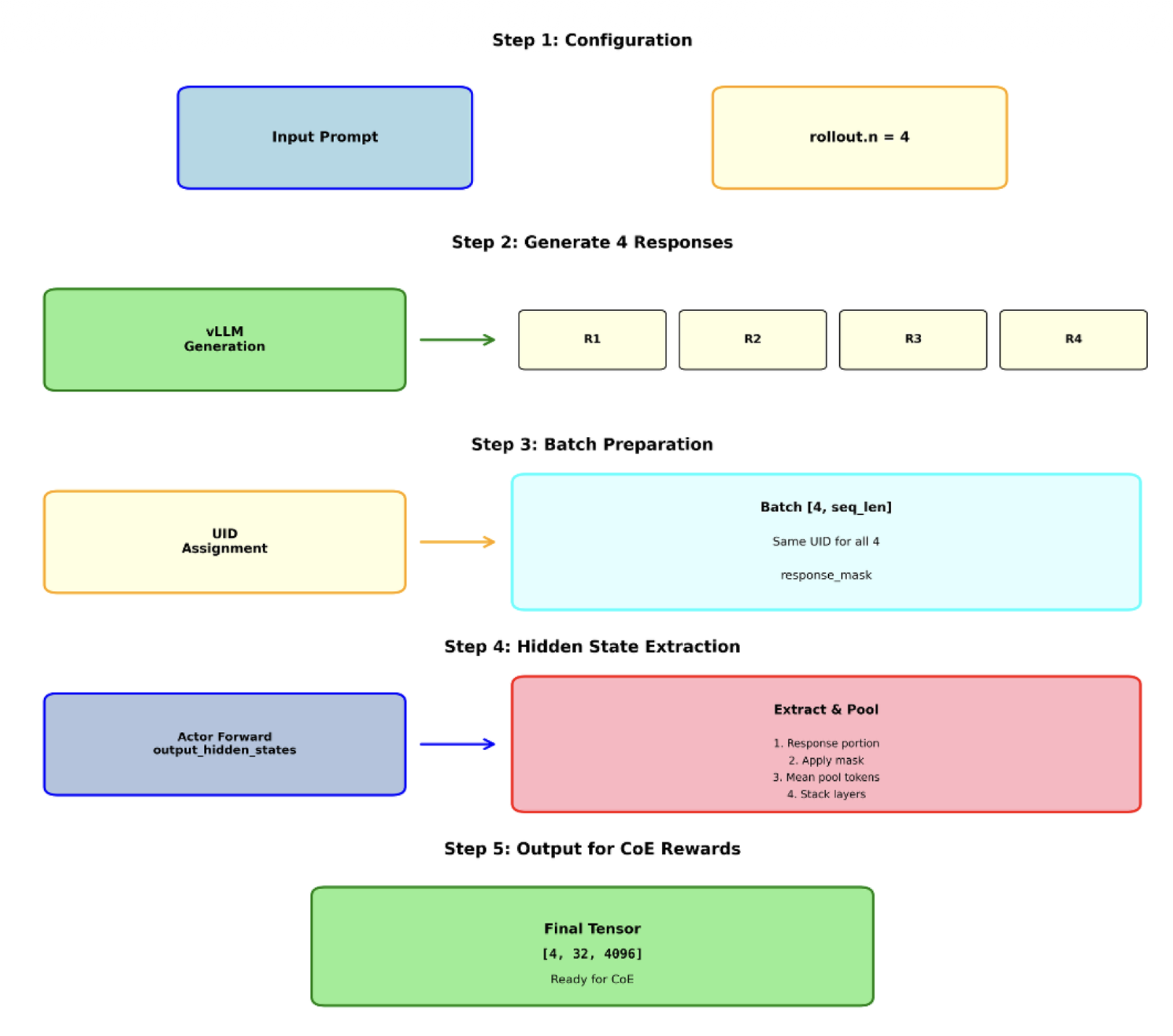
Abbildung 2.1: Extraktion der Hidden States bei den Schichten
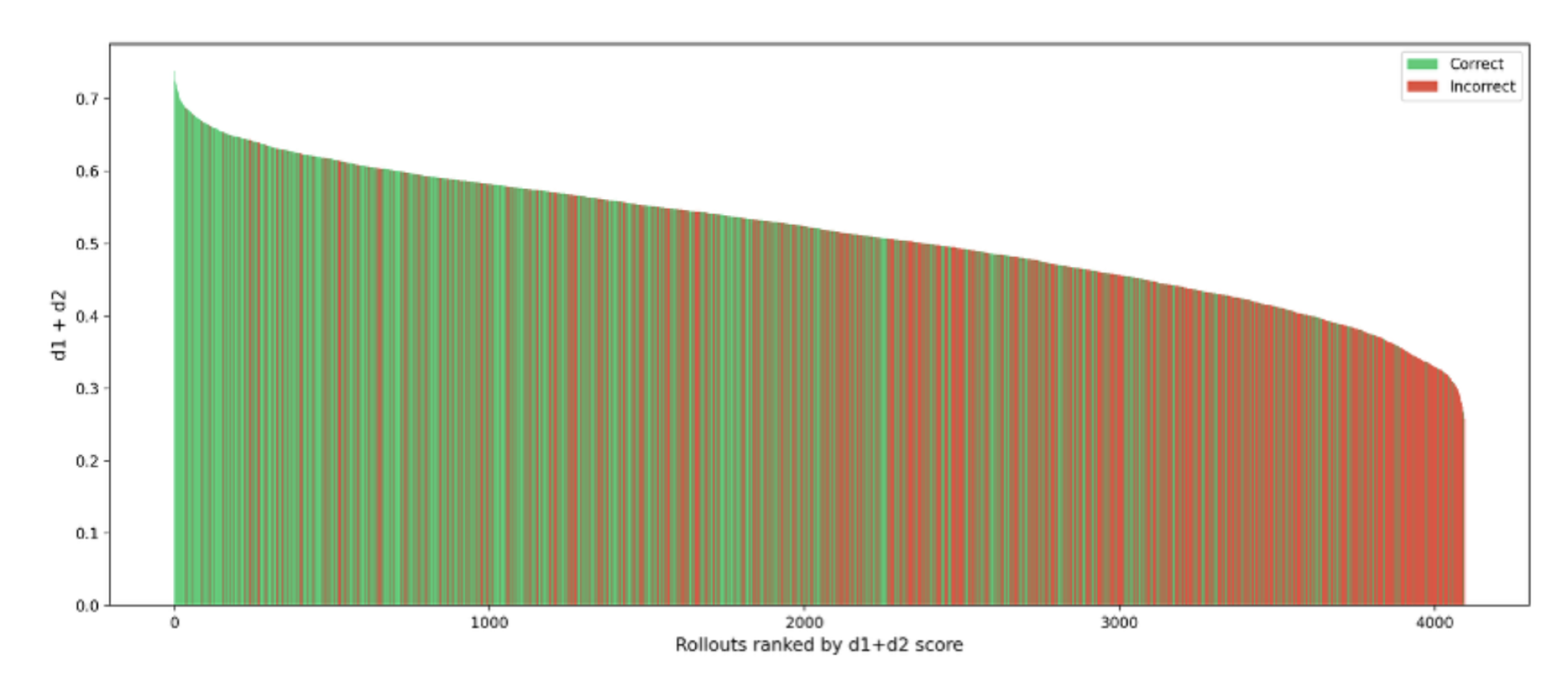
Abbildung 2.2: Korrelation zwischen Energie und Korrektheit der Responses bei dem 1.5 Milliarden Parameter Model
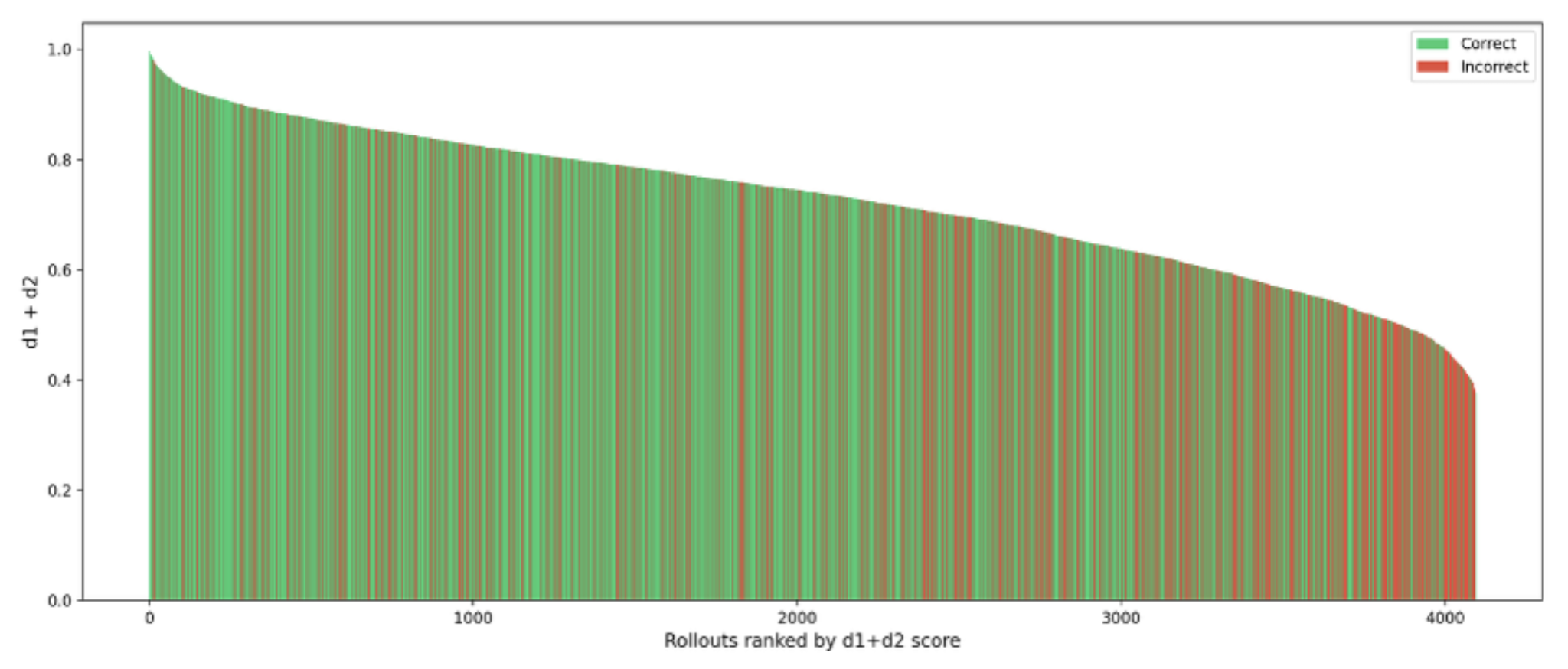
Abbildung 2.3: Korrelation zwischen Energie und Korrektheit der Responses bei dem 3 Milliarden Parameter Model
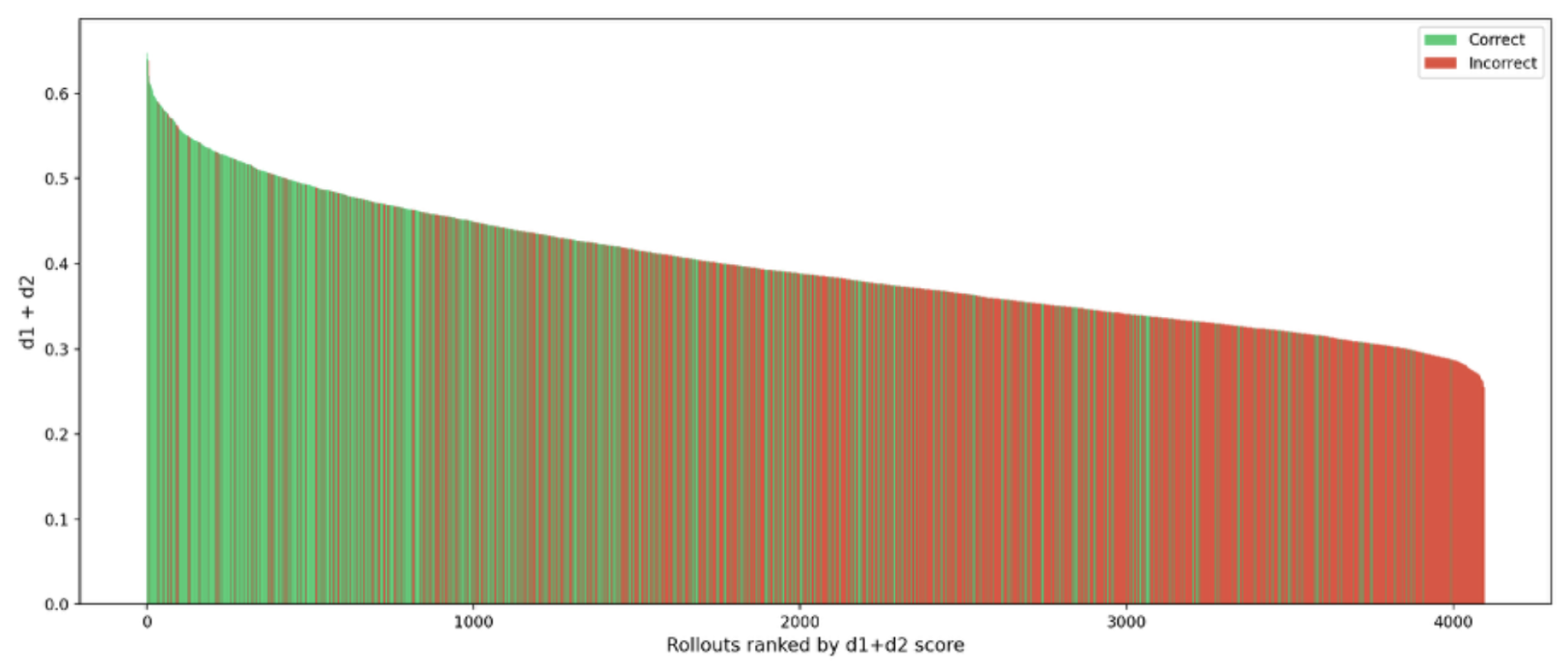
Abbildung 2.4: Korrelation zwischen Energie und Korrektheit der Responses bei dem 7 Milliarden Parameter Model
Ergebnisse und Erkenntnisse
Die Analysen offenbaren eine deutliche Korrelation zwischen der internen Energie E und der Korrektheit der Model Antworten. Antworten mit höherem E-Wert – also fließenderen, konsistenten Zustandsänderungen – waren signifikant häufiger korrekt. Besonders das 7B-Modell zeigte dabei die klarste Trennung zwischen korrekten und inkorrekten Antworten.
Das bedeutet: Gute Antworten entstehen, wenn sich das Modell intern gleichmäßig und zielgerichtet bewegt, nicht zu abrupt, aber auch nicht zu träge. Diese Erkenntnis ist nicht nur theoretisch spannend, sondern auch praktisch relevant. Sie könnte künftig genutzt werden, um Sprachmodelle intern zu überwachen, Unsicherheiten vorherzusagen oder Antworten nach ihrer „inneren Stabilität“ zu bewerten. Damit liefert die Arbeit einen wichtigen Beitrag zu transparenter, erklärbarer und vertrauenswürdiger KI – einem der zentralen Ziele moderner KI-Forschung.
Hier geht es zur Masterarbeit:
"Learning from Within: Hidden-State Dynamics as Rewards for Training LLMs"
Sie möchten mehr über KI-Lösungen von Accso erfahren?
Kontaktieren Sie uns – wir freuen uns auf den Austausch!